
인코딩 기반 우회 공격을 정규화하여 원래 의도를 복원
- Base64 / URL 인코딩 디코딩
- 유니코드 호몰로글리프 정규화
- Leet Speak / 다국어 우회 복원
AI 가드레일은 LLM의 입력과 출력 사이에 위치하여, 위험한 프롬프트와 응답을 즉시 탐지하고 차단하는 안전장치입니다. 21개 카테고리 · 149개 정책 · 1300+ 방어 규칙이 LLM의 입력과 출력을 즉시 검사합니다.
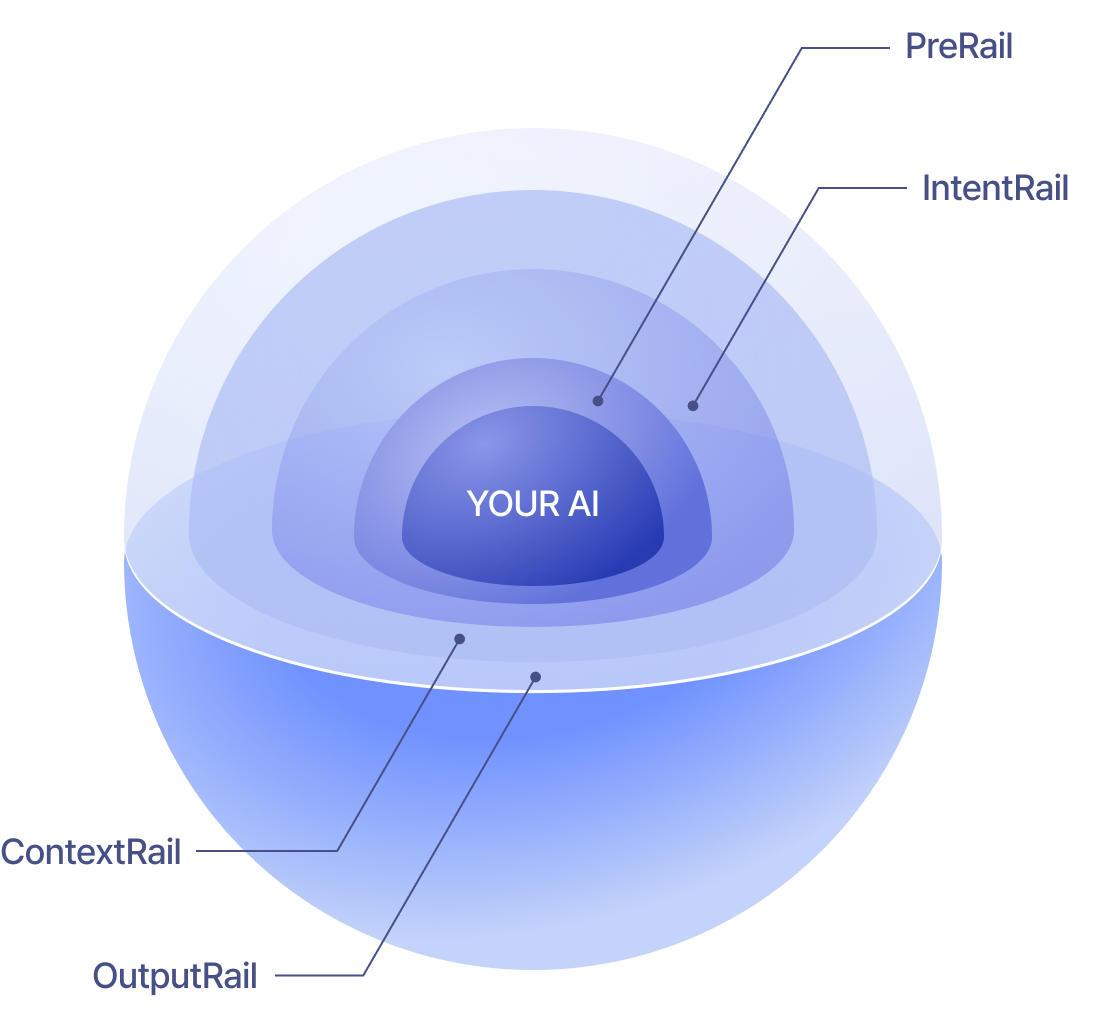
가드레일 체인은 사용자 요청부터 LLM 응답까지 전 구간을 이중 검증하는 파이프라인입니다. 입력 단계에서는 PreRail·IntentRail·ContextRail이 의도와 맥락을 분석해 잠재 위협을 선별하고, 출력 단계에서는 OutRail이 PII 및 내부 프롬프트 유출 여부를 검증합니다. 이를 통해 안전하지 않은 콘텐츠가 사용자에게 전달되기 전에 선제적으로 제어합니다.
* 위험 항목을 클릭하여 상세 내용을 확인해 보세요.
프롬프트 인젝션, 권한 상승, 시스템 정보 탈취 등 LLM 보안을 직접 위협하는 공격을 탐지합니다. OWASP LLM01, LLM07 대응.
AI 챗봇 서비스에서 발생하는 탈옥 공격, 유해 응답 생성, 브랜드 이미지 훼손을 방어합니다. 사용자가 역할극이나 감정 조작으로 가드레일을 우회하려는 시도를 IntentRail에서 즉시 탐지합니다.
S 보안 위협 / J 탈옥 우회 / H 유해 콘텐츠 / T 독성 표현 / B 브랜드
미성년자가 사용하는 교육 서비스에서 아동에게 부적절한 콘텐츠가 노출되지 않도록 보호합니다. 아동 보호(K) 카테고리는 민감도 0.95로 가장 엄격하게 설정하는 것을 권장합니다.
K 아동 보호 / H 유해 콘텐츠 / X 성적 콘텐츠 / A 접근성
국가안보에 민감한 정보 유출을 방지하고, 산업별 규제를 준수합니다. 사이버범죄 관련 정보 요청과 개인정보 탈취 시도를 차단합니다. 데이터가 외부로 나가지 않도록 로컬 LLM 연동을 권장합니다.
N 국가안보 / S 보안 위협 / C 규제 미준수 / D 개인정보 / W 사이버범죄
다국어 환경에서 문화적 감수성을 위반하거나 특정 인종, 종교, 성별에 대한 편향적 응답이 생성되지 않도록 합니다. 다국어 우회 공격도 탐지합니다.
M 다국어 / P 편향 공정성 / T 독성 표현 / E 윤리 위반
전체 21개 카테고리를 모두 활성화합니다. 최고 수준의 보안이 필요한 서비스에 적합합니다. 카테고리별 민감도를 개별 조정하여 오탐을 최소화할 수 있습니다.
단일 검증에 의존하지 않고, 여러 탐지 단계를 중첩 적용하는 Defense-in-Depth 구조입니다.
인코딩 기반 우회 공격을 정규화하여 원래 의도를 복원
키워드로 의심 대상을 걸러내고, LLM이 맥락을 분석해 최종 판단
멀티턴 대화 흐름에서 점진적 유도 공격을 탐지
LLM 응답을 사용자에게 전달하기 전 최종 검증

21개 카테고리 중 필요한 것만 켜고 끌 수 있어, 서비스 특성에 맞게 조절 가능합니다.
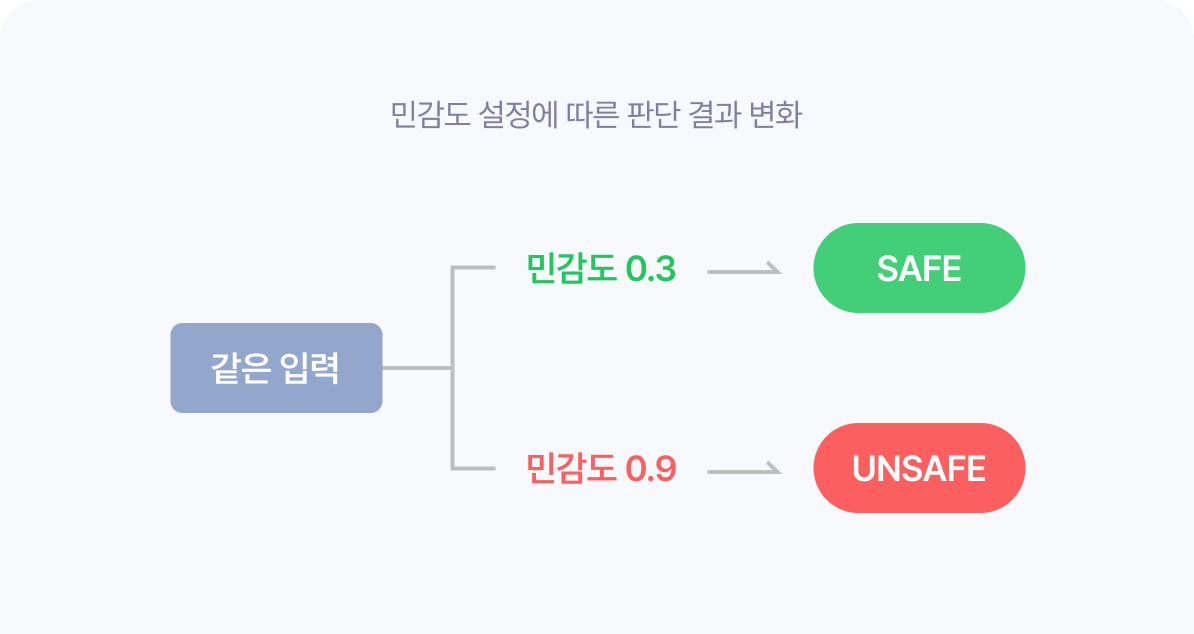
같은 입력이라도 민감도에 따라 결과가 달라집니다. 카테고리별로 0.0(관대)~1.0(엄격)의 설정값을 조정할 수 있습니다.
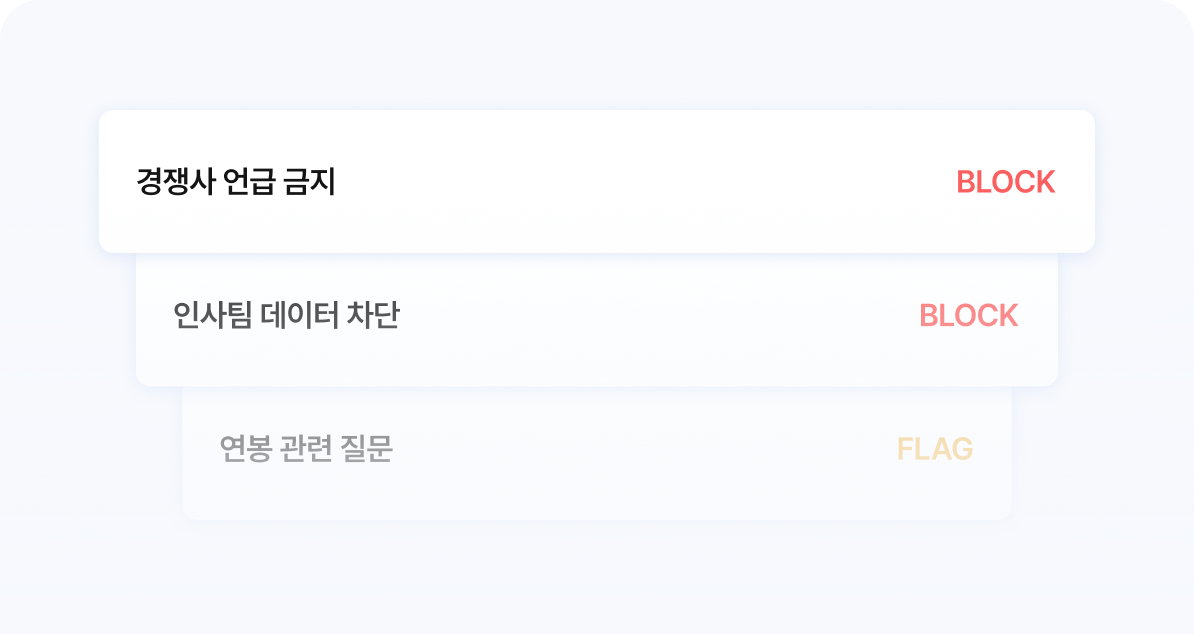
기업 고유의 차단 규칙을 정의합니다. IntentRail 안에서 가장 먼저 검사됩니다. block/flag 액션 선택이 가능합니다.
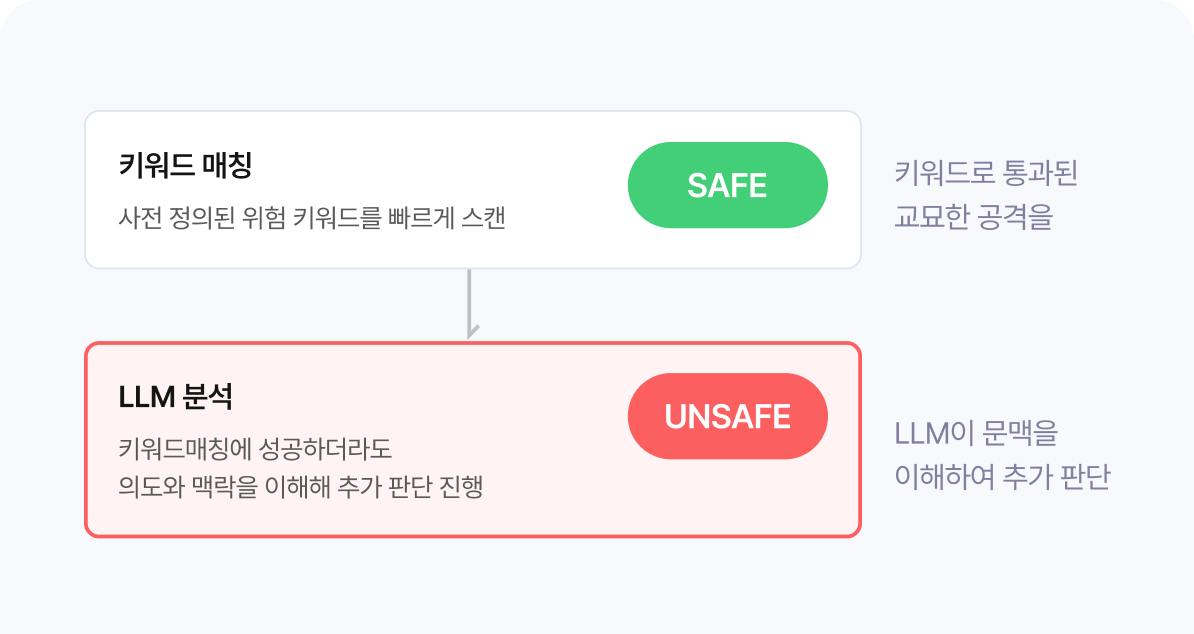
키워드 매칭으로 의심된 입력을 LLM이 맥락을 이해하여 최종 판단합니다. 일상 대화는 통과하고, 실제 위험 의도만 차단합니다.(선택 사항)
pip install 후 코드 3줄이면 가드레일이 작동합니다.
from guardrail_chain import GRCClient grc = GRCClient(config_path="./config.json") result = grc.check("사용자 입력 텍스트") if result.is_unsafe: print(f"차단: {result.label}") else: response = llm.generate(user_input)
서비스 환경과 보안 요구사항을 분석하고, 적합한 플래그 카테고리 구성을 제안합니다.
플랜에 맞는 라이선스를 발급하고, pip install guardrail-chain으로 SDK를 설치합니다.
config.json에서 카테고리, 민감도, 커스텀 룰을 설정하고, 기존 코드에 grc.check() 한 줄을 추가합니다.
검사 로그 기반으로 오탐/미탐을 분석하고, 민감도와 규칙을 지속적으로 최적화합니다.
HTTP 요청으로 어떤 언어에서든 호출할 수 있습니다.
// 요청 POST /v1/check { "text": "사용자 입력", "sensitivity": 0.7 } // 응답 { "label": "UNSAFE", "score": 0.95, "category": "탈옥" }
서비스 환경과 보안 요구사항을 분석하고, 적합한 플래그 카테고리 구성을 제안합니다.
플랜에 맞는 API 키를 발급합니다. 요청 시 헤더로 포함합니다.
POST /check 엔드포인트에 HTTP 요청을 보내고, JSON 응답을 수신합니다.
API 검사 로그와 호출 통계를 기반으로 규칙을 조정합니다.
모든 플랜은 동일한 4-Rail Pipeline을 사용합니다. 1 크레딧 = 1 check() 호출
테스트, 개인 프로젝트
소규모 서비스, 스타트업
중견 기업, 본격 운영
대기업, 맞춤 구축